Declarative APIs for Declarative UIs: Pagination as state
List backed APIs for paging in Jetpack Compose
TJ Dahunsi
Apr 26 2024 · 19 mins

My favorite part of developer relations was research. Given a certain API, my job was to collect feedback on it, investigate ways it may be improved, and relay that information back to the owning teams.
I did this as part of the architecture and testing developer relations team for about 3 years, specifically for Jetpack libraries in the UI layer and how they could better support Jetpack Compose. The opus of my tenure was the tagline "declarative APIs for declarative UIs", which was the advocacy for more idiomatic UI and data layer APIs to make building with Compose easier and faster.
The rest of this blog is the result of my research, investigation and advocacy for paging in Jetpack Compose neatly summarized into what I call the five Hs of pagination:
Hypothesis: A
Listbased pagination API should be possible.Hysteresis: What about a user's scrolling behavior over time can help build a pagination pipeline?
Heuristics: What are some system design options for building a pagination API?
Handling: How easy is the API to use?
Horsepower: How performant is the API?
The result is a List based experimental paging library that is as performant as the Jetpack Paging library, with its own unique set of compromises.
Hypothesis
One of the most common UI elements in apps is a collection view. In Jetpack Compose, it may be a List, Grid, StaggeredGrid or even a Pager. All of these components expose an index based API. For lists, grids and staggered grids, its generally something of the form:
open fun items( count: Int, key: ((index: Int) -> Any)? = null, contentType: (index: Int) -> Any = { null }, itemContent: @Composable LazyItemScope.(index: Int) -> Unit ): Unit
For pagers, its the following:
HorizontalPager(state = pagerState) { page -> // Page content Text( text = "Page: $page", modifier = Modifier.fillMaxWidth() ) }
These APIs allude to being backed by a data structure that can provide constant time access, or at least close enough to it to function properly, i.e, a List. What happens when the amount of items is arbitrarily large however? What does the optimal API for consuming paginated data in Jetpack Compose look like? Is it still List based?
I posit: yes. This is my hypothesis.
Hysteresis
Hysteresis is the dependence of the state of a system on its history, sometimes one where the effect of a change lags the cause of that change.
Consider a large, possibly infinite set of paginated data where a user is currently viewing page p, and n is the buffer count: the number of extra pages lazy loaded in case the user wants to visit it. In such a scenario, the pages can be represented as:
[..., p - n, ..., p - 1, p, p + 1, ..., p + n, ...]
As the user moves from page to page, i.e they scroll, items can be refreshed around the user's current page, while evicting items too far for the user to see. This is expanded in the diagram below:
[out of bounds] -> Evict from memory _ [p - n - 1 - n] | ... | -> Keep pages in memory [p - n - 1] _ _| [p - n] | ... | [p - 1] | [p] | -> Load pages [p + 1] | ... | [p + n] _| _ [p + n + 1] | ... | -> Keep pages in memory [p + n + 1 + n] _| [out of bounds] -> Evict from memory
The hysteresis relationship therefore is:
Cause: The user scrolling.
Effect: The asynchronous loading of items around the user's position.
Heuristics
A heuristic is a practical, yet inexact way of approaching a problem. This may be because the amount of variation in the system may be so high, that a true optimum path is hard to rigidly define. This is true for paging to some degree, as user input and intention is unpredictable. Following from the preceding section, hysteresis may be used to narrow the heuristics applied:
In the data layer:
Strict data layer: Data produced by the data source will always be valid. Data from previous loads will never be commingled with current loads.
Lax data layer: The data layer provides no guarantees about data at any point in time, but will include enough metadata in the provided data to allow for the UI to define its own logic for how data should be presented.
In the UI layer:
Index based paging: The current page
pis determined by the most recently accessed index for an item in the presentation API in the UI.Active viewport based paging: The current page
pis determined by the items visible in the viewport of the UI at any point in time. Items at indices may be accessed for reasons outside of pagination and do not affect paging.
The choice of which has interesting effects on the paging pipeline and the APIs they expose.
The heuristics of the Jetpack Paging library
Strict data layer heuristics
Any data materialized in the UI layer by the paging library will always be valid at the point of materialization. No duplicates, no mismatched data for different queries; it is pristine. This guarantee is one of the reasons why the exposed type from the data layer, PagingData, is an opaque black box that cannot be mutated outside of its transformation API.
To guarantee this, changes in the underlying data invalidates the current data source, causing a new one to be created and for paging to begin from the new one. This is fine for many scenarios, however for use cases like paginated freeform search, or filtering search results where the data set hasn't changed, but the window into the data set has, this means creating a new Pager instance with the new window parameters. If placeholders were used, this can mean the new Pager will displace existing data with placeholders before new data shows up.
Index based UI layer heuristics
In both Paging2 and Paging3, accessing an item at a certain index in a backing DataSource or PagingSource in the case of the latter, is a signal that items should be loaded around that position and a boundary condition may have been met. However there is no guarantee that an item actually exists at that position at a given point in time; it may return null or the item. If null is returned, a signal has been sent to fetch more if it exists. That is, accessing an item at a position has the side effect of possibly loading more items.
The major difference between the two is that Paging2 separated this side effect in the presentation API. In Paging2, the presentation API was backed by an actual Collection type, a PagedList. The side effect of loading more could be triggered explicitly using the loadAround method on the PagedList, or implicitly by the AsyncPagedListDiffer when connected to a PagedListAdapter. Paging3 streamlined this by introducing a new presentation API, PagedData, and its Compose wrapper LazyPagingItems. In doing so it:
Did away with the
loadAroundmethod. Item index triggered the side effect of loading more by default.To opt out of this behavior, a
peekmethod is provided onLazyPagingItemsPagingDataAdapterwith aRecyclerView.
This is largely fine when using a RecyclerView. PagingDataAdapter as it explicitly does not allow setting stable ids because it diffs items internally with an AsyncPagingDataDiffer, and the item content type is provided at ViewHolder creation.
In Compose however, the key and contentType arguments for lazy layouts don't have a differ abstraction, and the lazy layout API accessing an index to ascertain the key or contentType does not necessarily mean those items are ready to be laid out, breaking assumptions made by the paging library about the side effects that should occur. This is why when using LazyPagingItems, accessing the key or contentType at a certain position uses a special method so as to not accidentally trigger a page load. A page load should only be triggered by actually displaying an item in that position. For example, the itemContentType() method follows, note its use of peek():
public fun <T : Any> LazyPagingItems<T>.itemContentType( contentType: ((item: @JvmSuppressWildcards T) -> Any?)? = null ): (index: Int) -> Any? { return { index -> if (contentType == null) { null } else { val item = peek(index) if (item == null) PagingPlaceholderContentType else contentType(item) } } }
The choice of this heuristic makes for a few rules when using Paging3:
LazyPagingItemsis not a generalListdata structure and should not be treated as such. There are bugs that exist when trying to use it with sticky headers by iterating over it and trying to create aMapfor sticky headers and this should generally be avoided.Transformation should only be done using the explicit transformation APIs provided as they will always use the right APIs to do the right things.
The only reasonable consumer of
PagedDataorLazyPagingItemsis the UI, other layers of the app cannot consumePagingData. You can't readPagingDatain the data or domain layers for example.There is implicitly only one placeholder
keyorcontentTypefor items that have not been loaded and it is not user defined. i.e, you cant have different kinds of placeholders even if you're loading heterogeneous items.
The heuristics of the Tiling library
So what changes would I make to the paging library to make it a more idiomatic fit for Compose and modern app development? A few:
App readable API: The exposed data type from the data layer should be readable anywhere in the app, not just the presentation layer, i.e the data layer should expose a
Flow<Item>>instead of a bespoke type.UI layer validated heuristics for the data layer: The UI layer should be the final arbiter for what it displays, the data layer lacks enough context to decide what can be presented.
Immutable presentation API for the UI layer: The presentation API should be an immutable
List<Item>. Reasons to be detailed in the "handling" section.Separations of concerns: logic like retrying, and loading completely be absent from the presentation API. These calls should go through the appropriate state holder like a
ViewModel.Flexible transformations: At any point in time, the
Listpresented may be transformed in any way with no penalties. It may be mapped, filtered, or even associated into aMap.Precise invalidation: If one item in the list has changed, I should not have to write to the database or backing data source to have it materialize in the UI. I should be able to surgically edit the items displayed.
This can be achieved by a process called tiling.
Lax data layer heuristics
Given a data layer API of the form:
data class ItemQuery( val text: String, val offset: Long, val limit: Long, ) interface ItemRepository { fun itemsMatching(query: ItemQuery) : Flow<List<Item>> }
It should be transformable downstream to a modestly sized sublist of items that fit about 4 - 7 pages defined for the current viewport.
As each query returns a Flow, the data layer can not guarantee the integrity of the data; consumers can transform it however they like. The data layer itself may even emit duplicate items downstream depending on the implementation backing Flow for each query. To provide enough metadata for the UI layer to enforce that the data it has is presentable, metadata must be provided in the materialized List in the UI layer. This metadata laden List implementation is called a TiledList and is produced by a ListTiler:
fun interface ListTiler<ItemQuery, Item> { fun produce( inputs: Flow<Tile.Input<ItemQuery, Item>> ): Flow<TiledList<ItemQuery, Item>> }
Use is through an extension function on a Flow<Tile.Input> which is then transformed to the Flow<TiledList>>:
val pageRequestFlow = MutableSharedFlow<Tile.Input<Int, Item>>() val items: Flow<TiledList<Int, Item>> = pageRequestFlow.toTiledList( listTiler( order = Tile.Order.PivotSorted( comparator = compareBy(Int::compareTo) ), limiter = Tile.Limiter( maxQueries = 3 ), fetcher = { page -> repository.itemsFor(page) } ) )
The TiledList
A TiledList is a List implementation that:
Is a sublist of the items in the backing data source.
Allows for looking up the query (page) that fetched each item.
The latter is done by associating a range of indices in the List with a Tile. Effectively, a TiledList "chunks" its items by query. For example, the TiledList below is a List with 10 items, and two tiles. Each Tile covers 5 indices:
| 1 | 2 |
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A Tile is a value class with the following public properties:
value class Tile(...) { // start index for a chunk val start: Int // end exclusive index for a chunk val end: Int }
Making it possible to define a TiledList as:
interface TiledList<Query, Item> : List<Item> { /** * The number of [Tile] instances or query ranges there are in this [TiledList] */ val tileCount: Int /** * Returns the [Tile] at the specified tile index. */ fun tileAt(tileIndex: Int): Tile /** * Returns the query at the specified tile index. */ fun queryAtTile(tileIndex: Int): Query /** * Returns the query that fetched an [Item] at a specified index. */ fun queryAt(index: Int): Query }
Active view port based UI layer heuristics
To produce this TiledList, the view port is monitored and fetches data based on what is currently seen, regardless of what indices have been accessed in the backing TiledList, i,e the TileList is unable to trigger side effects by reading from it.
There are multiple inputs that may go into the pipeline. The basic ones are:
Tile.Request.On(query): Analogous toputfor aMap, this starts collecting from the backing Flow for the specified query. It is idempotent; multiple requests have no side effects for loading, i.e the same Flow will not be collected twice.Tile.Request.Off(query): Stops collecting from the backingFlowfor the specified query. The items previously fetched by this query are still kept in memory and will be in the TiledList of items returned. Requesting this is idempotent; multiple requests have no side effects.Tile.Request.Evict(query): Analogous toremovefor aMap, this stops collecting from the backing Flow for the specified query and also evicts the items previously fetched by the query from memory. Requesting this is idempotent; multiple requests have no side effects.
In Compose, these inputs are generated using an Effect Composable. This provides a callback for what query is currently in the view port and this information can be fed back to the ViewModel to fetch more data:
@Composable fun <Query> LazyListState.PivotedTilingEffect( items: TiledList<Query, *>, indexSelector: IntRange.() -> Int = kotlin.ranges.IntRange::first, onQueryChanged: (Query?) -> Unit ) fun <Query> PagerState.PivotedTilingEffect( items: TiledList<Query, *>, onQueryChanged: (Query?) -> Unit )
With the current query in the view port identified, a series of On, Off and inputs can be generated and sent off to the ListTiler to produce TiledList instances. This can be done manually, but is easier to delegate to a special Tile.Input: Tile.Order.PivotSorted(query). It is a special Tile.Input that acts as a batch input and it will generate the appropriate Tile.Request instances internally.
Handling
There are several reasons to go through all the trouble of the declaration above as the following uses cases in the table below summarize:


For large screened devices:
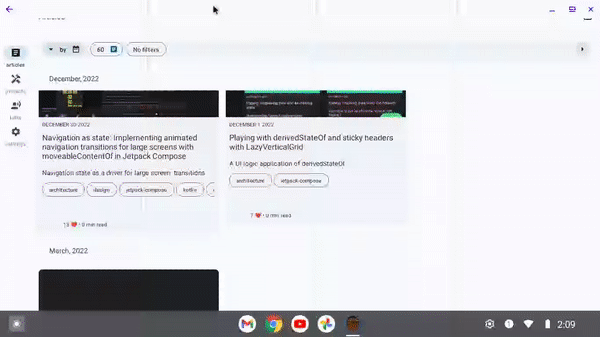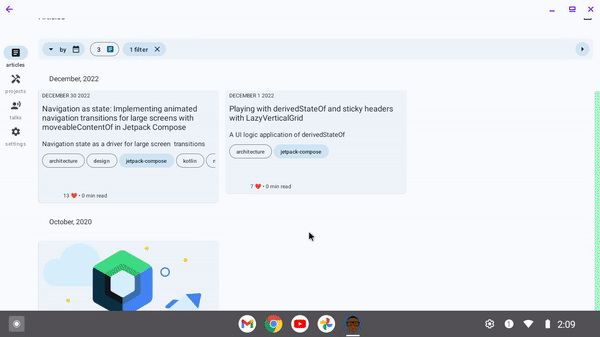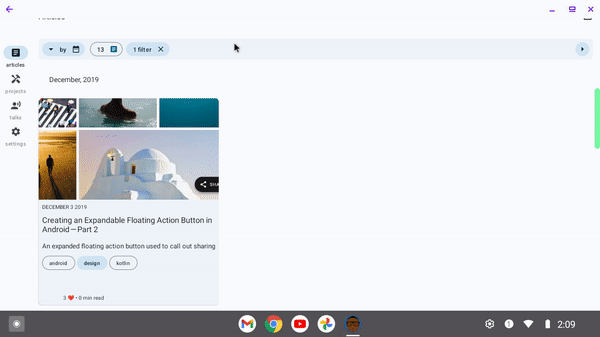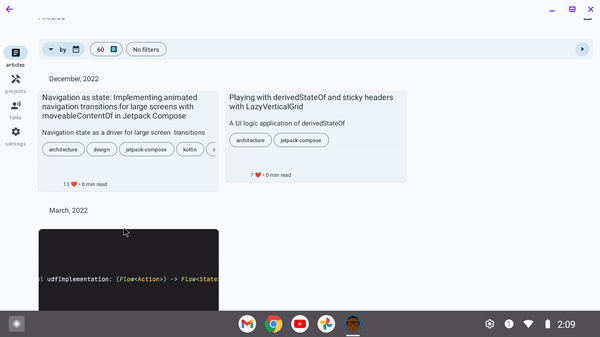
Please see the documentation for more details.
Let's go into a few:
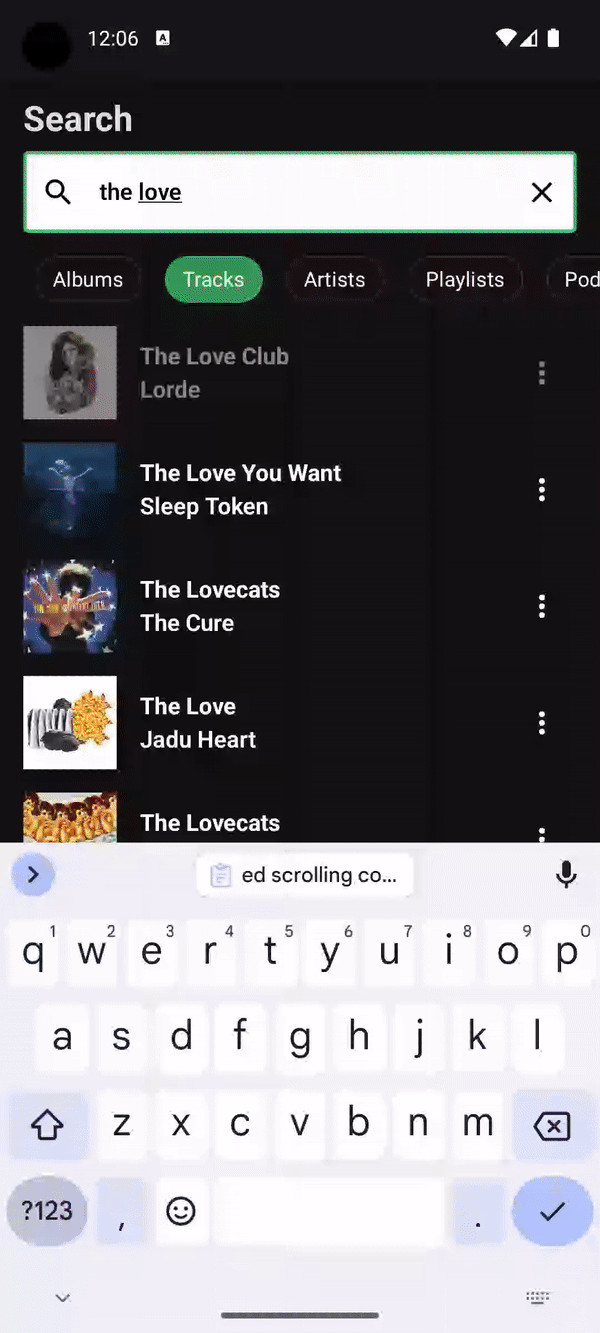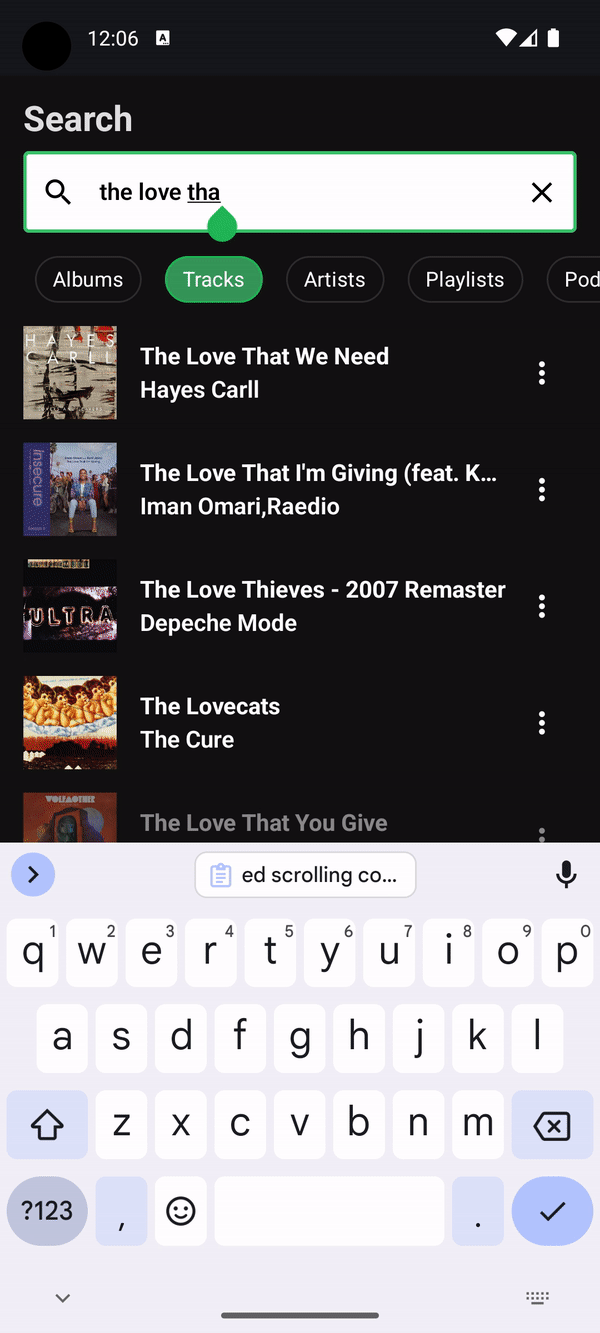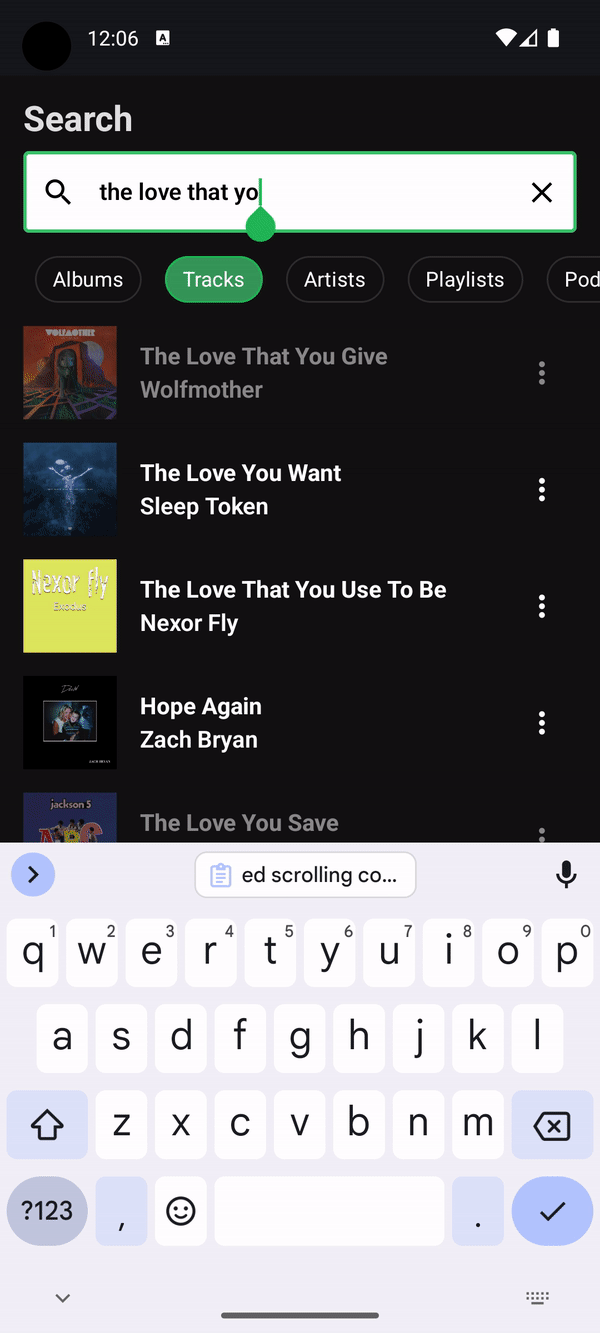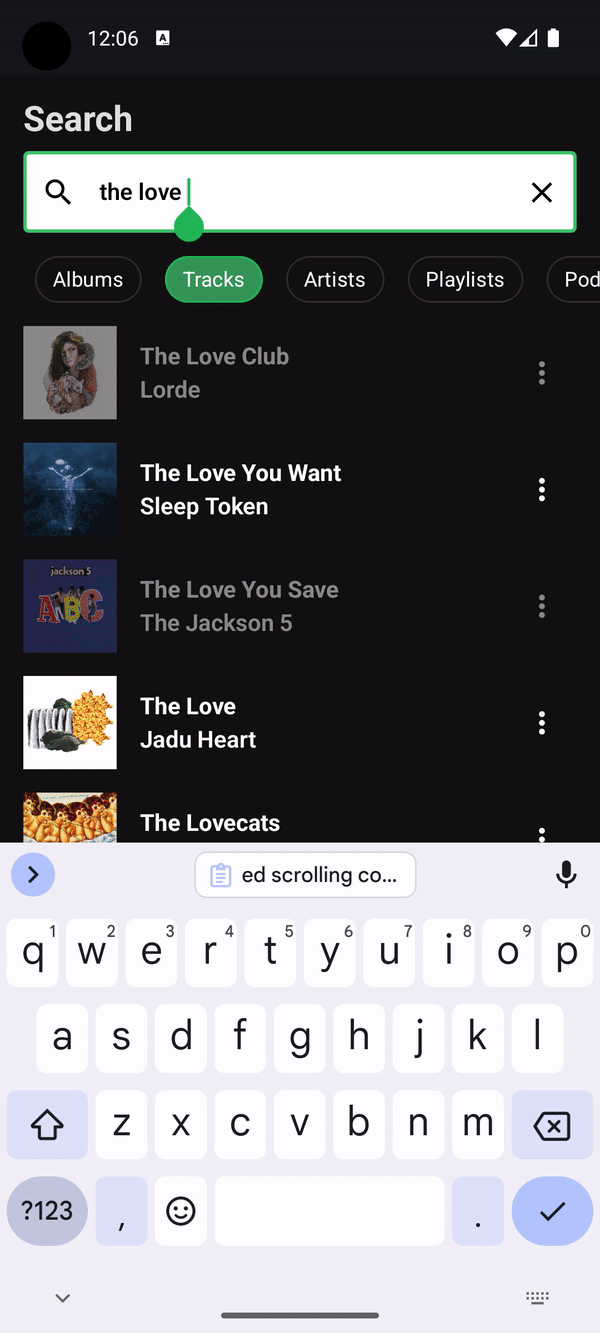
Search
Compose 1.7.0 brings lazy list item removal animations, and they really shine with Tiling when used in a remake of Spotify's search in Compose:
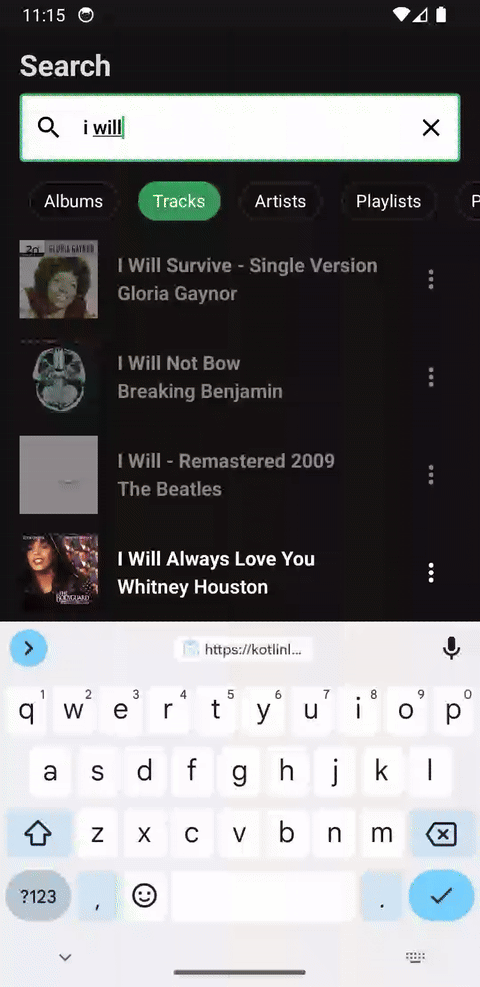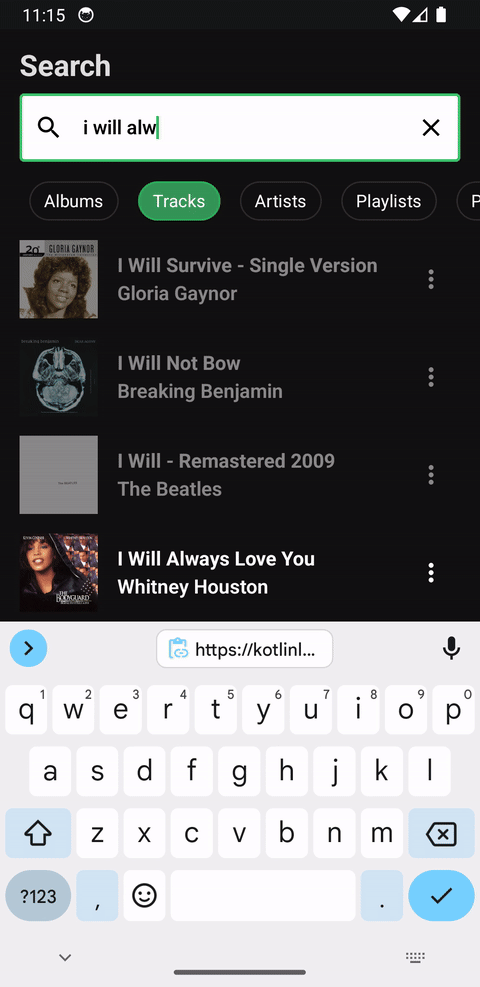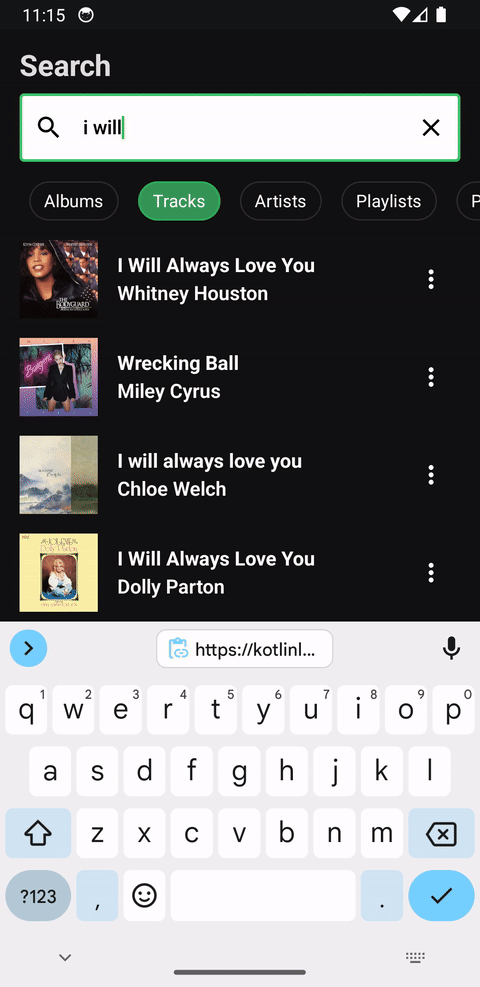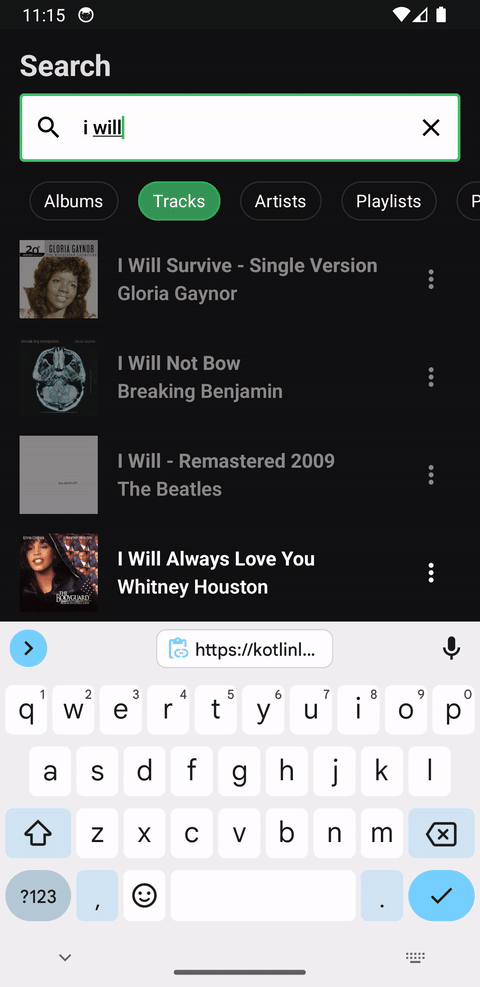
For each new character typed, a new paging pipeline needs to be created because the query has fundamentally changed. However because the output of the paging pipeline is a Flow<TiledList<Query, Item>>, the output Flow can be debounced and inspected to only allow the new items fetched to be presented when animations can be run against them and the last presented items. In this scenario, only the UI layer is aware of what items it already has, and therefore should be allowed to determine when items are materialized. This is something that isn't possible with PagingData as a Flow<PagingData> cannot be introspected to get a debounce signal because of its opacity.
Furthermore, it can be used in a StateFlow with preseeded initial values without issues. The pagination pipeline can be stopped and restarted using the appropriate stateIn argument without needing to keep it active a CoroutineScope when the UI is not present.
private inline fun <reified T : SearchResult> MutableStateFlow<ContentQuery>.toTiledList( scope: CoroutineScope, initialValue: TiledList<ContentQuery, SearchItem<T>>, searchRepository: SearchRepository ): StateFlow<TiledList<ContentQuery, SearchItem<T>>> { val startPage = value.page return debounce { // Don't debounce the If its the first character or more is being loaded if (it.searchQuery.length < 2 || it.page.offset != startPage.offset) 0 // Debounce for key input else 300 }.toNetworkBackedTiledList( startQuery = value ) { query -> if (query.searchQuery.isEmpty()) emptyFlow() else searchRepository.searchFor(query) .map<SearchResults, List<T>>(SearchResults::itemsFor) } .map { tiledItems -> if (tiledItems.isEmpty()) tiledListOf(value to SearchItem.Empty) else tiledItems // The data layer cannot guarantee unique items .distinctBy(SearchResult::id) .map { SearchItem.Loaded(it) } } .debounce { tiledItems -> // If empty, the search query might have just changed. // Allow items to be fetched for item position animations if (tiledItems.first() is SearchItem.Empty) 350L else 0L } .stateIn( scope = scope, started = SharingStarted.WhileSubscribed(5_000), initialValue = initialValue ) }
Shared Elements
[Source code](https://github.com/tunjid/listingApp?open-graph-search=true]
Also in Compose 1.7.0 are primitives for building shared element transitions, as well as full support for shared element transitions with SharedTransitionLayout, Modifier.sharedElement() and Modifier.sharedBounds().
A crucial part of making shared elements work with navigation transitions, is being able to guarantee the existence of the shared element on the incoming screen is available on the first frame of the transition. For lists, this can only be done by seeding the initial state of the incoming screen to ensure it contains the key of the shared element. In the example below, navigation arguments contain string URLs that are used for an initial state for the shared element in a TiledList, then after the asynchronous load completes, the items are replaced with the loaded items with the same key.

This is more relevant after process death. Popping back after a list-detail navigation when the list destination is being restored means the backing ViewModel for the list screen was destroyed. At the time it is being recreated, the detail screen needs to be able to pass back state to the list screen to render its shared element transition. In the example below since navigation is state, The detail screen is able to write to the navigation state, and process its initial state for the shared element transition when popping back after process death.
Adaptive pagination
[Source code](https://github.com/tunjid/Tiler?open-graph-search=true]
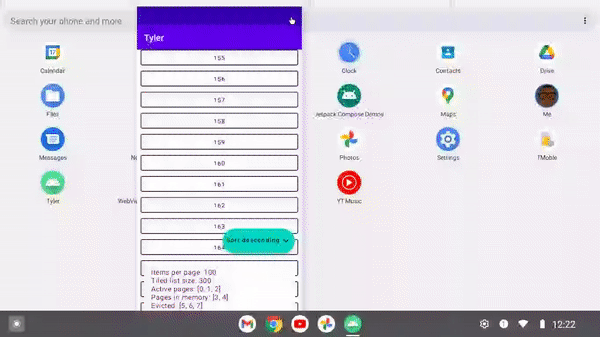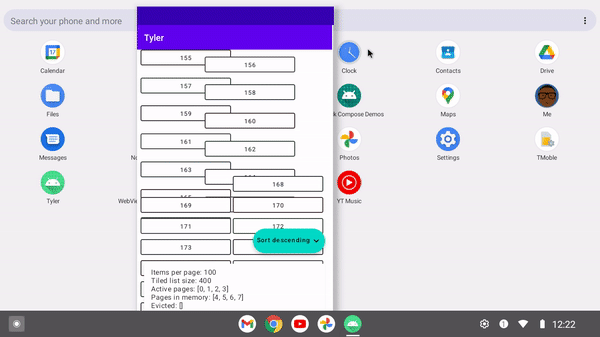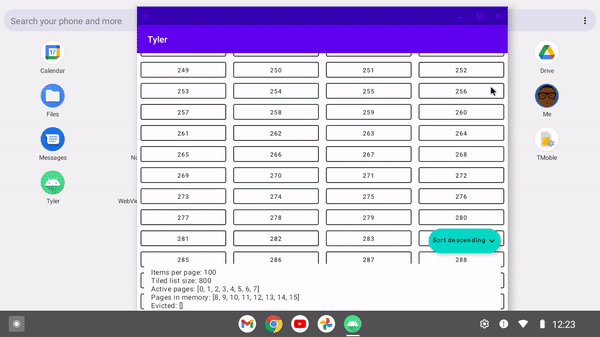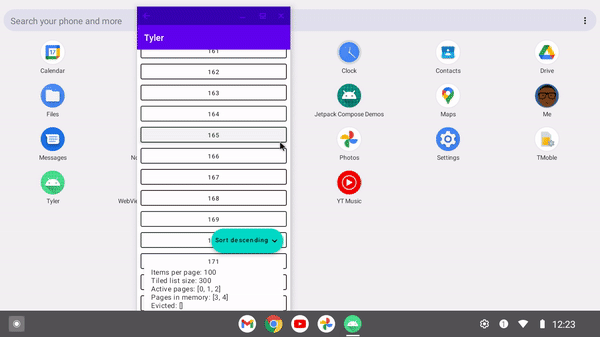
As foldable devices become more common, it's important to have architecture to support any given device configuration at a point in time. When a foldable device is shut, it may only need 10 items to fill its viewport. However when opened, it may accommodate up to twice that, and thus needs to update its paging configuration.
With a ListTiler, since the Flow<Tile.Input> can be updated at any time to make the amount of pages fetched match a dynamic screen configuration.
/** * Pivoted tiling with the grid size as a dynamic input parameter */ private fun pivotRequest( isAscending: Boolean, numberOfColumns: Int, ) = PivotRequest( onCount = 4 * numberOfColumns, offCount = 4 * numberOfColumns, nextQuery = nextQuery, previousQuery = previousQuery, comparator = when { isAscending -> ascendingPageComparator else -> descendingPageComparator } ) }
This can then be used to drive the example below:
Transformations
In the case of transformations, A TiledList instance can transformed by converting it to a MutableTiledList which has the definition:
interface MutableTiledList<Query, Item> : TiledList<Query, Item> { fun add(index: Int, query: Query, item: Item) fun add(query: Query, item: Item): Boolean fun addAll(query: Query, items: Collection<Item>): Boolean fun addAll(index: Int, query: Query, items: Collection<Item>): Boolean fun remove(index: Int): Item }
There are also convenience methods for map, mapIndexed, filter, filterIndexed and so on.
Horsepower
This conversation would be remiss not to mention the performance difference between both approaches discussed. The details follow, but the only conclusion I could reach was tiling is not less performant than paging. If anything, it is more performant in more scenarios, but the differences are so minimal they're largely inconsequential. See below for details.
Random access
The following table summarizes random access performance for a paginated pipeline with pages retrieved p, with a total items count of n.
Action | Paging | Tiling | Explanation |
|---|---|---|---|
Accessing item index i | In paging, items per page are indeterminates, so each page has to be "walked" to find the index of an item. In tiling a | ||
Triggering load more at item index i | Paging similarly needs to "walk" to find the page for the index that was accessed. Tiling uses a spare array like data structure to look up queries for a page with binary search. |
Microbenchmarks
Microbenchmark testing on Android allows for a limited comparison between both approaches purely from an object allocation perspective. While time is also recorded in a microbenchmark test, the difficulty of reading from PagingData and AsyncPagingDataDiffer sets up an unfavorable comparison in favor of Tiling.
The microbenchmark results are presented with detailed explanations following. The benchmarks were run on a Google Pixel Fold.
Run 1 configuration:
Items per page | Num pages in memory | Page to scroll to |
|---|---|---|
100 | 3 | 20 |
Run 1 results:
Test | Approach | Allocations |
|---|---|---|
Scroll to page | Paging | 7215 |
Scroll to page | Tiling | 8495 |
Invalidate offscreen pages | Paging | 8651 |
Invalidate offscreen pages | Tiling | 8495 |
Invalidate onscreen pages | Paging | 11176 |
Invalidate onscreen pages | Tiling | 8979 |
Run 2 configuration:
Items per page | Num pages in memory | Page to scroll to |
|---|---|---|
100 | 7 | 20 |
Run 2 results:
Test | Approach | Allocations |
|---|---|---|
Scroll to page | Paging | 6131 |
Scroll to page | Tiling | 7685 |
Invalidate offscreen pages | Paging | 15563 |
Invalidate offscreen pages | Tiling | 7685 |
Invalidate onscreen pages | Paging | 17968 |
Invalidate onscreen pages | Tiling | 9073 |
Run 3 configuration:
Items per page | Num pages in memory | Page to scroll to |
|---|---|---|
100 | 10 | 20 |
Run 3 results:
Test | Approach | Allocations |
|---|---|---|
Scroll to page | Paging | 5247 |
Scroll to page | Tiling | 8364 |
Invalidate offscreen pages | Paging | 27421 |
Invalidate offscreen pages | Tiling | 8364 |
Invalidate onscreen pages | Paging | 32239 |
Invalidate onscreen pages | Tiling | 10867 |
Scroll to page
This test starts paging from page 0 and continues until page 20 is reached. Both approaches are fairly similar here, with paging creating less objects.
Invalidate offscreen pages
Similar to the scroll benchmark, however once page 20 is reached, the paging pipeline is invalidated for a range of pages. The thing to note here is precision. Tiling emits from a Flow per page, so if that page is not being collected from because it is too far offscreen, no new items will be produced. For paging invalidating the datasource causes a new generation of items to be emitted regardless of if the change is visible or not.
Invalidate onscreen pages
Similar to the offscreen benchmark but new items are actually produced. In this case, only pages that are invalidated produce items, so allocation is minimal in tiling compared to paging. The same caveat applies in practice in that whatever optimization is gained in allocation is likely lost to CPU time comparing for distinctiveness.
Conclusion
Ultimately, the goal of this research project was to see if an efficient List based paging API was possible as I think it would be a much better idiomatic fit for Jetpack Compose. With Tiling performance at the very least as good as the paging library, I think I achieved that. Feasibility however, is not the only thing that matters.
The API, while flexible, is easy to misuse. If backing Flows for a page don't emit, the pipeline could get stuck. There's probably some refinement that can be done, but my job was to play developer advocate and ask the question of the engineering team "Can the paging library be much better if it presented a simple List?". Ithink the answer is yes, and now have an experiment that backs that opinion up too some degree.
Loading comments...